Transcription Template
When the time comes to transcribe corpus data (e.g., data from the Talk-a-Thon or Talk Together Study), you will be given an ELAN template file.
Contents
- Template contents
- How to import the template
- Tasks to complete prior to transcribing on the template file
- Tips
This template will contain the following:
- 4 Participant primary
Utterancetiers with accompanying secondary tiers (Chunk, Language, Target_EL, Target_CL, Target_ML, Target_TL, Translation, Matrix, Sensitive_Masking). See ‘A Guide To All Your Tiers’ for an overview of these tiers - 4 participants including: Baby, Mother, Father, Researcher
- 1
ActivityMarkerTier - 1
LanguagesControlled Vocabulary (See “Language Tag List” for full list) - 1
Matrix_LanguagesControlled Vocabulary (Contains all the same tags as the Languages Controlled Vocabulary except for ‘Red Dot’) - 1
Target_Words_MandarinControlled Vocabulary - 1
Target_Words_EngControlled Vocabulary - 1
Target_Words_MalayControlled Vocabulary - 1
Activity_MarkersControlled Vocabulary - 1
Sensitive_MaskingControlled Vocabulary - 12 tier types (
Lang_TimeSub, Chunk_TimeSub, Translation, Utterance, Target_Words_Eng_IncIn, Target_Words_Mandarin_IncIn, Target_Words_Malay_IncIn, Target_Words_Tamil_IncIn, Activity_Marker, Matrix_Lang, Sensitive_Masking_IncIn, Baby_Target_Words_IncIn)
Back to table of contents
To import the template file:
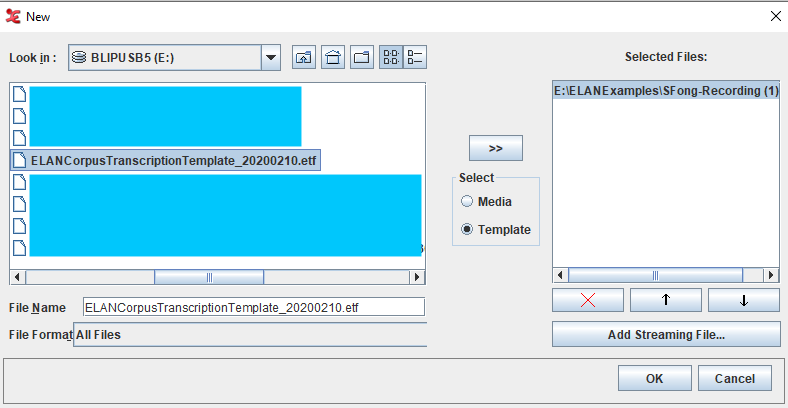
On Windows:
- Launch ELAN
- File > New
- Upload the media file. Press [»] to move it into the “Selected Files” box.
- Click “Template” (button below “Media” in the Select box)
- Select template file [insert file name here]. Press [»] to move it into the “Select Files” box.
- Press OK.
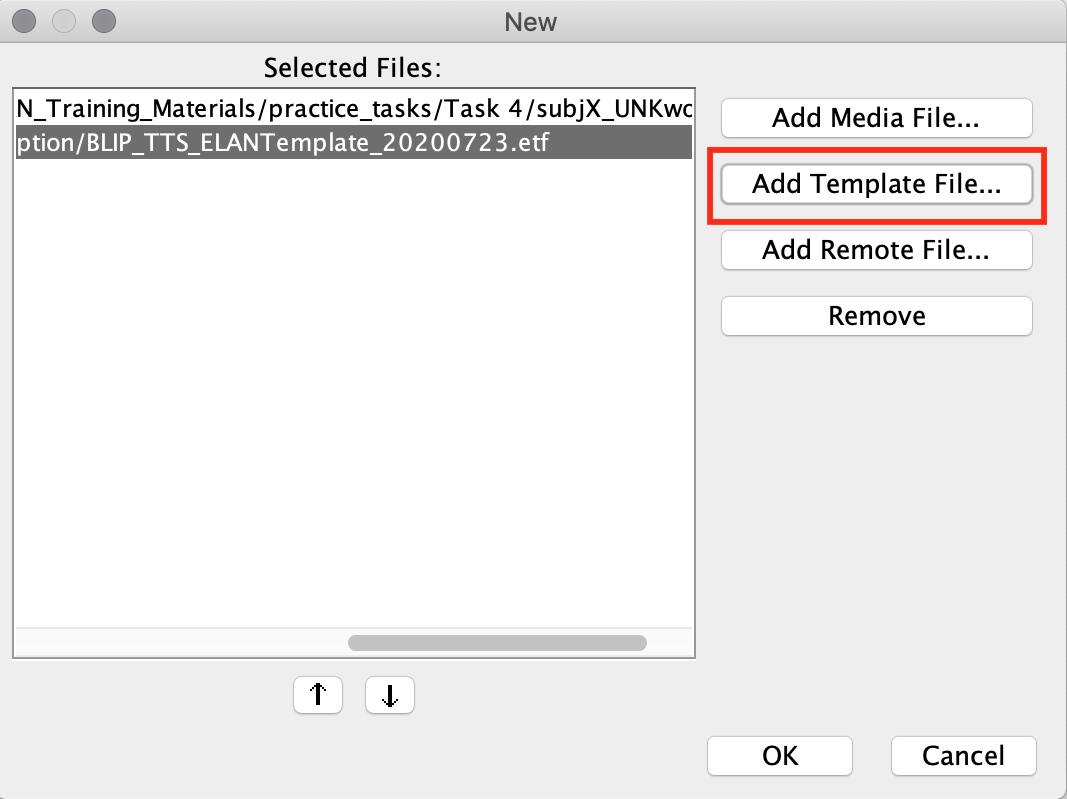
On Mac:
- Launch ELAN
- File > New
- Press “Add Media File…”. Select the media file to be annotated.
- Press “Open” to upload the media file.
- Press “Add Template File..” Select the template file.
- Press “Open” to upload the template file.
- Press OK.
Back to table of contents
Tasks to complete PRIOR to beginning to transcribe using the template file:
1. Check the README (if available) for contextual information (e.g., which participants are present, what languages are spoken, etc.)
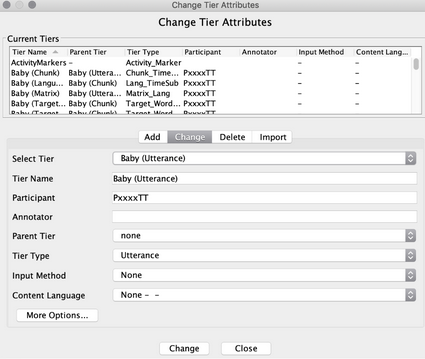
2. Edit the tiers to replace placeholders with accurate participant ID codes for all participants (See “A Guide To All Your Tiers” for full list of participant codes)
Go to Tier > Change Tier Attributes > Edit the “Participant” line (e.g., if the baby has a Child ID of P1234TT, their participant line for all of their tiers should be changed from PxxxTT to P1234TT. Similarly, the baby’s mother’s participant line should be changed from MPxxxTT to MP1234TT.
In the case of the researcher, edit their “Tier name” and “Participant line” to reflect their researcher code. For example, if the researcher who worked with P1234TT has a researcher code of R111, their tier name should be renamed from R00X to R111, and their participant line should be changed from R00XPxxxxT to R111P1234TT.
3. Generate any new participant tiers if necessary (e.g., if theres more than one Unknown individual).
* See [Transcribing Dependent Tiers](/belacon/archive/2.0.0a21ELAN/fundamentals/transcribing-dependent-tiers.html), with instructions on how to create new dependent tiers
* See [A Guide to All Your Tiers](/belacon/archive/2.0.0a21ELAN/protocols/tier-guide.html) for the tier type stereotypes and hierarchical relationships of each tier needed. Consult your supervisor if you are having issues (especially with assigning the correct tier type stereotypes).
Back to table of contents
Tips during the transcription process [WIP]:
Discovered any helpful tips not listed here? Please let your supervisor know!
-
Watch our
Things to Keep in Mind While Transcribing TTS Datavideo here -
Too many tiers getting in the way? Hide them!
-
Hover over the specific tier > right click > Hide
[participant_name](Tier Name). -
To reveal the hidden tier: hover over the tier sidebar > Visible Tiers > check the checkbox of the hidden tiers to reveal them
-
Back to table of contents