A Guide to all your tiers
The following sections explain each tier in more detail. While the template already contains most of the potential participants and their corresponding necessary tiers, please use the below information when creating new tiers for new participants. All the tier types will have already been set up in the template. Should you have any questions, please go to your supervisor.
We will need ten (10) tiers per participant. These tiers will be known as the Utterance Tier, Chunk Tier, Language Tier, Target_EL Tier, Target_CL Tier, Target_ML Tier, Target_TL Tier, Translation Tier, Matrix Tier, Sensitive_Masking Tier. The Utterance tier will be the primary (parent) tier of the Chunk, Translation, Matrix, and Sensitive_Masking Tiers. The Chunk Tier will be the primary tier of the Language, Target_EL, Target_CL, Target_ML, and Target_TL tiers.
The photo below illustrates the complete hierarchical/tier dependent relationship of the tiers for each of the participants.

We will also need an independent ActivityMarkers tier.
Contents
- Utterance Tier
- Chunk Tier
- Language Tier
- Target_EL Tier
- Target_CL Tier
- Target_ML Tier
- Target_TL Tier
- Translation Tier
- Matrix Tier
- Sensitive_Masking Tier
- Baby Tiers
- Activity Marker Tier
- Sibling Tier (if necessary)
- Participant Codes
Utterance Tier
Video guide to utterance tier here
Purpose: This tier will transcribe all utterances in terms of what is being said. It will be a single tier with no sub-divisions.
Naming: Tag the tier “[person_name] (Utterance)”. The complete name should look like Mother (Utterance).
Parent (primary) tier: none
Tier Type: Utterance (i.e., no stereotype, no use of controlled vocabulary)
Back to table of contents
Chunk Tier
Video guide to chunk tier here. Live demo video on how to sub-divide cells on the chunk tier here.
Purpose: This tier will transcribe all utterances in terms of what is being said, but cells can be subdivided should there be instances of interjections, vocal sounds, non-vocal sounds, or code-switching.
Naming: Tag the tier “[person_name] (Chunk)”. The complete name should look like Mother (Chunk).
Parent (primary tier): “[person_name] (Utterance)”
Tier Type: Chunk_TimeSub (Time Subdivision stereotype, no use of controlled vocabulary)
Back to table of contents
Language Tier
Video guide on the language tier here.
Purpose: This tier is for transcribing utterances in terms of what fine-grained language is spoken. For example, let us look at the sentence “他喜欢吃 hamburger” (translation: he likes to eat hamburgers). “他喜欢吃” (translation: he likes to eat) will be labelled as ‘Mandarin’ but “hamburger” will be labelled as English. This tier differs from the Matrix tier (see Matrix Tier sub-section).
Naming: Tag the tier “[person_name] (Language)”. The complete name should look like Mother (Language).
Parent (primary) tier: “[person_name] (Chunk)”
Tier Type: Lang_TimeSub (Time Subdivision sterotype, Languages controlled vocabulary)
Back to table of contents
Target_EL Tier
Video guide on all target language tiers here.
Purpose: EL stands for ‘English’. This tier is for transcribing ‘target’ English words from the Picture Cards (Vowel Triangle) activity. The four (4) target English words can be found here. These are included in a controlled vocabulary assigned to the tier type of any adult Target_EL tier. However, the tier type for Baby (Target_EL) does not have a controlled vocabulary, so as to allow the transcriber to freely transcribe any instance of the baby’s attempt at vocalising a target word (e.g., if a baby says ‘pwee’ instead of ‘pea’).
Naming: Tag the tier “[person_name] Target_EL”. The complete name should look like Mother (Target_EL).
Parent (primary tier): “[person_name] (Chunk)”
Tier Type for adult tiers: Target_Words_Eng_IncIn (Included in stereotype, Target_Words_Eng controlled vocabulary)
Tier Type for baby tiers: Baby_Target_Words_IncIn (Included in stereotype, no controlled vocabulary)
Back to table of contents
Target_CL Tier
Video guide on all target language tiers here.
Purpose: CL stands for ‘Mandarin’. This tier is for transcribing ‘target’ Mandarin words from the Picture Cards (Vowel Triangle) and Green Grass Park Voicemail Game activity. These are included in a controlled vocabulary assigned to the tier type of any adult Target_CL tier. However, the tier type for Baby (Target_CL) does not have a controlled vocabulary, so as to allow the transcriber to freely transcribe any instance of the baby’s attempt at vocalising a target word.
The eleven (11) target Mandarin words for the Picture Cards activity can be found here.
The target Mandarin words for the Green Grass Park Voicemail Game activity can be found here (click to enlarge picture).
Naming: Tag the tier “[person_name] Target_CL”. The complete name should look like Mother (Target_CL).
Parent (primary tier): “[person_name] (Chunk)”
Tier Type for adult tiers: Target_Words_Mandarin_IncIn (Included in stereotype, Target_Words_Mandarin controlled vocabulary)
Tier Type for baby tiers: Baby_Target_Words_IncIn (Included in stereotype, no controlled vocabulary)
Back to table of contents
Target_ML Tier
Video guide on all target language tiers here.
Purpose: ML stands for ‘Malay’. This tier is for transcribing ‘target’ Malay words from the Picture Cards (Vowel Triangle) and Green Grass Park Voicemail Game activity. These are included in a controlled vocabulary assigned to the tier type of any adult Target_ML tier. However, the tier type for Baby (Target_ML) does not have a controlled vocabulary, so as to allow the transcriber to freely transcribe any instance of the baby’s attempt at vocalising a target word.
The four (4) target Malay words for the Picture Cards activity can be found here.
The target Malay words for the Green Grass Park Voicemail Game activity can be found here (click to enlarge picture).
Naming: Tag the tier “[person_name] Target_ML”. The complete name should look like Mother (Target_ML).
Parent (primary tier): “[person_name] (Chunk)”
Tier Type for adult tiers: Target_Words_Malay_IncIn (Included in stereotype, Target_Words_Malay controlled vocabulary)
Tier Type for baby tiers: Baby_Target_Words_IncIn (Included in stereotype, no controlled vocabulary)
Back to table of contents
Target_TL Tier
Video guide on all target language tiers here.
Purpose: TL stands for ‘Tamil’. This tier is for transcribing ‘target’ Tamil words from the Picture Cards (Vowel Triangle) and Green Grass Park Voicemail Game activity. Unlike the other Target tiers, there is temporarily no controlled vocabulary for the Tamil target words. This is because the ELAN software does not have the functionality (yet) to input Tamil script into the controlled vocabulary window. In the meantime, all Tamil target words must be inputted directly (i.e., typed) on the tiers. The tier type for Baby (Target_TL) also does not have a controlled vocabulary, so as to allow the transcriber to freely transcribe any instance of the baby’s attempt at vocalising a target word.
The four (4) target Tamil words for the Picture Cards activity can be found here.
The target Tamil words for the Green Grass Park Voicemail Game activity can be found here (click to enlarge picture)
Naming: Tag the tier “[person_name] Target_TL”. The complete name should look like Mother (Target_TL).
Parent (primary tier): “[person_name] (Chunk)”
Tier Type for adult tiers: Target_Words_Tamil_IncIn (Included in stereotype, no controlled vocabulary)
Tier Type for baby tiers: Baby_Target_Words_IncIn (Included in stereotype, no controlled vocabulary)
Back to table of contents
Translation Tier
Video guide to translation tier here.
Purpose: This tier will contain English translations of non-English utterances. A loose translation of the utterance will suffice i.e., enough information for an outside English reader to understand what is going on.
A person who reads the translation tier will be someone who does not speak the language. Translate the utterance into English as if you were trying to explain it to someone who does not speak the language.
Naming: Tag the tier “[person_name] (Translation)”. The complete name should look like Mother (Translation).
Parent (primary) tier: “[person_name] (Utterance)”
Tier Type: Translation (Symbolic Association stereotype, no use of controlled vocabulary)
Back to table of contents
Matrix Tier
Video guide on matrix tier here.
THIS TIER CAN CURRENTLY BE IGNORED AND NOT BE USED. HOWEVER, DO NOT DELETE IT!
Purpose: In contrast to the Language tier that focuses on the fine-grained language spoken in the utterance, the Matrix tier focuses on transcribing the language that encapsulates the utterance. While both Mandarin and English are spoken in the sentence “他喜欢吃 hamburger” (Translation: He likes to eat hamburgers), the Matrix language will be Mandarin. This is because “hamburger” (English) is embedded into the utterance’s Mandarin sentence structure.
The name of this tier was inspired by the concepts of matrix clauses and subordinate clauses. For an easy-to-understand explanation of these concepts, please read this post from AllThingsLinguistic.
Naming: Tag the tier “[person_name] (Matrix)”. The complete name should look like Mother (Matrix).
Parent (primary) tier: “[person_name] (Utterance)”
Tier Type: Matrix_Lang (Symbolic Association stereotype, Matrix_Languages controlled vocabulary)
Back to table of contents
Sensitive_Masking Tier
Video guide on Sensitive_Masking here. Live demo on how to use the Sensitive_Masking tier here.
Purpose: This tier is for isolating and annotating instances in the audio file that needs redaction. It is assigned a controlled vocabulary of redaction codes that the transcriber can choose from. Annotating instances on this tier means that it will be essentially “censored” with a beep when the audio recording is released to the public (like songs that contain expletives or when someone says a swear word on television).

Instances that should be redacted include:
| Instance | Redaction Code |
|---|---|
| Baby’s name | BABYNAME |
| Baby’s sibling’s name | SIBLINGNAME |
| An adult’s name | ADULTNAME |
| Baby’s father’s name | FATHERNAME |
| Baby’s mothers’s name | MOTHERNAME |
| Baby’s grandmother’s name | GRANDMOTHERNAME |
| Baby’s grandfather’s name | GRANDFATHERNAME |
| A stranger’s name (e.g., classmate, co-worker) | STRANGERNAME |
| Pins, passwords, personal discussions, study IDs | CONFIDENTIAL |
| Candidate for redaction and to alert supervisor/second transcriber to check | :PROTECTION-CHECK |
Things to note:
-
Names of individuals on the research team do not need to be redacted.
-
Any mention of the baby’s name must always be redacted as BABYNAME on the
Utterance,Chunk, andSensitive_Maskingtier. -
If it is ever unclear as to who the name belongs to, transcribe the name on the
UtteranceandChunktiers (also theTranslationtier, if applicable) as:n:[attempt at spelling the name]. For example, if the speaker said “Jillian went to the supermarket” but it was not clear that Jillian was the baby’s grandmother from the context of the conversation, you should transcribe it as:n:Jillian went to the supermarketon theUtteranceandChunktiers. You should also isolate and annotate the instance of Jillian as:PROTECTION-CHECKon theSensitive_Maskingtier. Using this convention will alert the transcript checker (i.e., a full-time staff member) to match it to a list of possible caregiver names that we have on record, and annotate it with the corresponding redaction code accordingly on theSensitive_Maskingtier.
For more information on how to handle privacy matters during transcription, please read the privacy matters section of the wiki.
Naming: Tag the tier “[person_name] (Sensitive_Masking)”. The complete name should look like Mother (Sensitive_Masking).
Parent (primary) tier: “[person_name] (Utterance)”
Tier Type: Sensitive_Masking_IncIn (Included in stereotype, Sensitive_Masking controlled vocabulary)
Back to table of contents
Baby Tiers
Due to the nature of this project, most recordings will involve a baby. The baby will have all ten aforementioned tiers. Any speech spoken by the baby should be transcribed and relevant tiers should be annotated on. However, baby’s vocalizations (e.g., babbling, cooing, etc.) will be recorded in a different way from that of adult participants. These transcription conventions are covered in the “List of Special Codes” section of the wiki.
Please make your best attempt at transcribing any instances of baby vocalisations. If the vocalisations are completely unintelligible or inaudible, transcribe it as ###.
Back to table of contents
Activity Marker Tier
Video guide to activity marker tier here.
This tier is to mark the start and end of a planned activity that takes place during the recordings. They delineate the start and end points of a parent’s response, and include researcher’s instructions for ads_ggp, cds_book, and growing_collection
The image below illustrates activity markers in place. The length of the activity marker annotations does not really matter, as long as there is an annotated cell. When processing the transcript, we take the left time point bolded in red as the start of the activity (note :marker:start:[activity_name]), and the right time point as the end of the activity (note :marker:end:[activity_name]).

Naming: Tag the tier “ActivityMarkers”. The complete name should look like ActivityMarkers.
Parent (primary) tier: none
Tier Type: Activity_Marker (i.e., no stereotype, Activity_Markers controlled vocabulary)
The format of the annotation to mark the start of the activity is :marker:start:[activityname]. The format of the annotation to mark the ending of the activity is :marker:end:[activityname].
The current list of Talk Together Study activities and coding conventions are as follows:
- Parent: Vowel Triangle in English (Picture Card)
ads_voweltri_Eng - Parent: Vowel Triangle in Preferred Language (Picture Card)
ads_voweltri_[languagename](e.g.,:marker:start:ads_voweltri_Mandarin) - Parent: Prompt Questions in English (Question on Card)
ads_prompts_Eng - Parent: Prompt Questions in Preferred Language (Question on Card)
ads_prompts_[languagename](e.g.,:marker:end:ads_prompts_Tamil) - Parent: Green Grass Park =
ads_ggp - Parent and Child: Green Grass Park =
cds_ggp - Parent and Child: StoryBook
cds_book - Parent and Child: Vowel Triangle in English (Word and Picture on Card)
cds_voweltri_English(e.g.,:marker:start:cds_voweltri_Eng - Parent and Child: Vowel Triangle in Preferred Language (Word and Picture on Card)
cds_voweltri_[languagename](e.g.,:marker:start:cds_voweltri_Malay) - Growing Collections Form
growing_collection(e.g.,:marker:start:growing_collection)
In some recordings, researchers may have had to follow up with parents on surveys the parents had previously filled out. In the event that this occurs in the recording you are transcribing, use the following coding convention to demarcate the start and end of this segment. Do ask a staff member if you are unsure.
- Survey follow-up
survey_follow_up(i.e.,:marker:start:survey_follow_upand:marker:end:survey_follow_up)
Note: ADS = “Adult-Directed Speech” and CDS = “Child-Directed Speech”
The complete list of activities and corresponding coding conventions have been compiled and are part of the Activity_Markers controlled vocabulary.
Back to table of contents
Sibling Tier (if necessary)
At times, siblings may appear and participate in the video call activities. If their voices can be heard clearly and they are part of the conversation of interest (e.g. storybook reading), new tiers should be added for the sibling.
The tiers will follow the same tier attributes and format of tier names as the other existing tiers in the template (Mother, Father, Baby, Researcher). Please do not edit or delete the existing tiers!
The tier names should be as follows:
- Sibling1 (Utterance)
- Sibling1 (Chunk)
- Sibling1 (Language)
- Sibling1 (Target_EL)
- Sibling1 (Target_CL)
- Sibling1 (Target_ML)
- Sibling1 (Target_TL)
- Sibling1 (Translation)
- Sibling1 (Matrix)
- Sibling1 (Sensitive_Masking)
If the ID for the recording is P1234TT, the participant code for the tier attributes should be SIB1P1234TT for all of the Sibling tiers.
There is a difference in transcription protocols and conventions when transcribing Baby and Adult speech. In order to decide which conventions should be used, this decision table should be used.
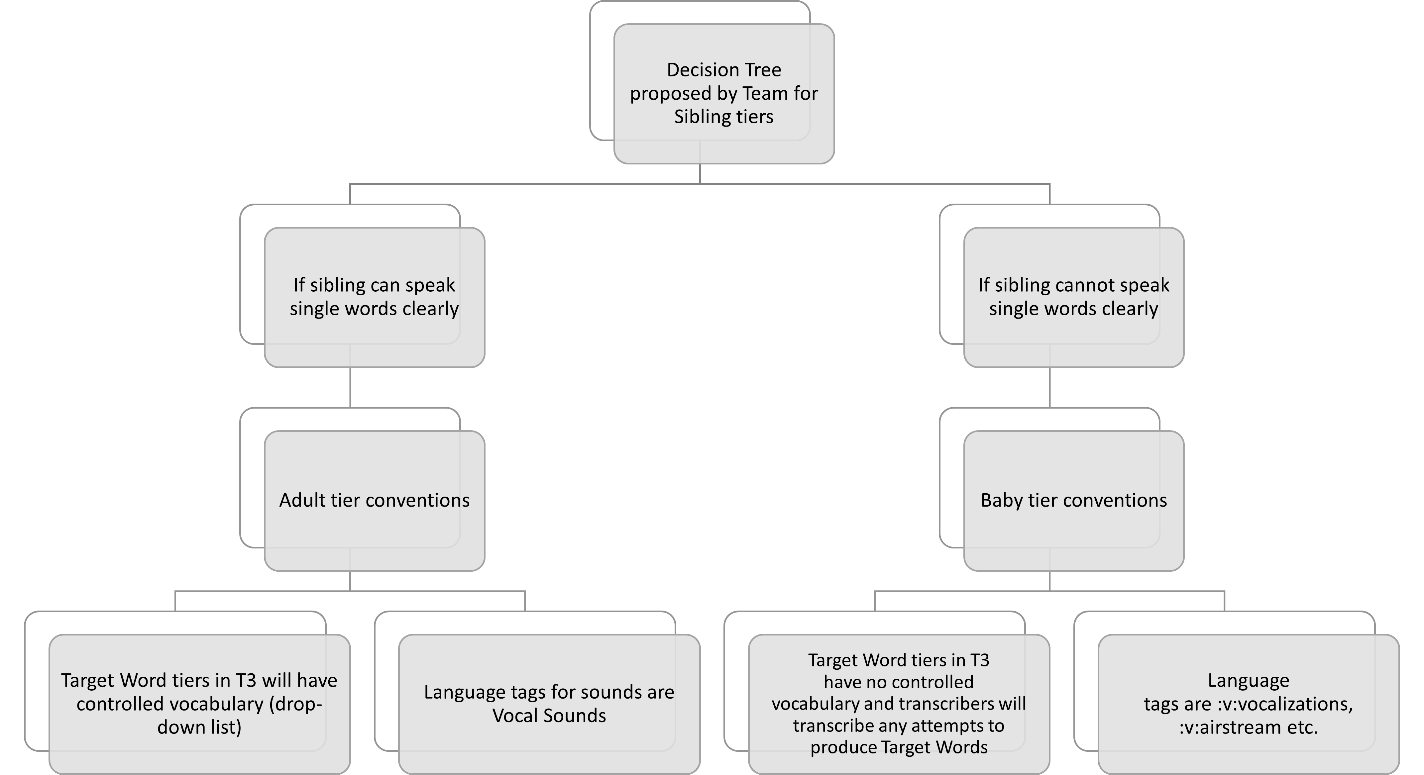
Back to table of contents
Participant Codes
When you create a tier, under Tier attributes, there is a section for Participants. Fill this in with the individual participant code respective to the project.
Note: The ELAN template for the Talk Together Study (TTS) already has placeholder codes entered, i.e., PxxxTT. The x’s will need to be replaced with the corresponding Child ID of the recording you are transcribing.
List of Tiers
[person_name][space](class)
List of person_name
Relatives
| Description | Participant Code | Pilot10 Example (BABYCODE = PR01) | TTS Example (CHILD ID = P1234TT) |
|---|---|---|---|
| Mother | M[BABYCODE/CHILD ID] | MPR01 | MP1234TT |
| Father | F[BABYCODE/CHILD ID] | FPR01 | MP1234TT |
| Grandmother1 | GM1[BABYCODE/CHILD ID] | GM1PR01 | GM1P1234TT |
| Grandmother2 | GM2[BABYCODE/CHILD ID] | GM2PR01 | GM2P1234TT |
| Grandfather1 | GF1[BABYCODE/CHILD ID] | GF1PR01 | GF1P1234TT |
| Grandfather2 | GF2[BABYCODE/CHILD ID] | GF2PR02 | GF2P1234TT |
| Sibling1, Sibling2 | SIB[NUMBER][BABYCODE/CHILD ID] | SIB1PR01 | SIB2P1234TT |
Other Adults
| Description | Participant Code | Pilot10 Example (BABYCODE = PR01) | TTS Example (CHILD ID = P1234TT) |
|---|---|---|---|
| Adult1, Adult2 | A[NUMBER][BABYCODE/CHILD ID] | A1PR01 | A1P1234TT |
Researchers
Each researcher has a specific code. Please ask a full-time staff member should you need a specific researcher’s code.
| Description | Participant Code | Pilot10 Example (BABYCODE = PR01) | TTS Example (CHILD ID = P1234TT) |
|---|---|---|---|
| R001, R002 | RA[NUMBER][BABYCODE/CHILD ID] | R001PR01 | R099P1234TT |
Unknown Person
| Description | Participant Code | Pilot10 Example (BABYCODE = PR01) | TTS Example (CHILD ID = P1234TT) |
|---|---|---|---|
| Unknown1, Unknown2 | U[NUMBER][BABYCODE/CHILD ID] | U1PR01 | U1P1234TT |
Annotator (Transcriber)
Note: Transcribers do not have a special participant code, but their participant field needs to be filled in with their initials (e.g., Bob Ross’ initials = BR).
| Description | Participant Code | Example |
|---|---|---|
| Transcriber | Annotator's Initials | Self-Explanatory |
List of class
- Utterance
- Chunk
- Language
- Target_EL
- Target_CL
- Target_ML
- Target_TL
- Translation
- Matrix
Examples of resultant tier names
- Mother (Utterance)
- Mother (Language)
- Mother (Target_TL)
- Mother (Translation)
- Grandmother1 (Utterance)
- Unknown1 (Utterance)
- Father (Matrix)
Back to table of contents