FAQs - Frequently Asked Questions
Frequently Asked Questions
Contents
- General
- Privacy
- Special codes and language-tagging
- Language Specific: Malay
- Language Specific: Mandarin
- Language Specific: Tamil
- ELAN specific questions
General
1. Defininition of word
An overview of what we at BLIP lab consider a word is outlined in this document here. It is by one of our Research Fellows, Dr. Shamala Sundaray.
For Chinese words, add spaces between words in the Chunk tier only.
For the Utterance tier, spaces should be placed to separate Chinese characters from text that aren’t Chinese characters. e.g., “she eats 那个 uh 大大的汉堡包 :v:laughter” (Translation: she eats that uh huge hamburger :v:laughter) should be written in the Utterance tier as she eats 那个 uh 大大的汉堡包 :v:laughter and NOT as she eats那个uh大大的汉堡包:v:laughter . The exception to this rule is question marks e.g. orangutan is sad 对不对? (Translation: orangutan is sad, isn’t it?).

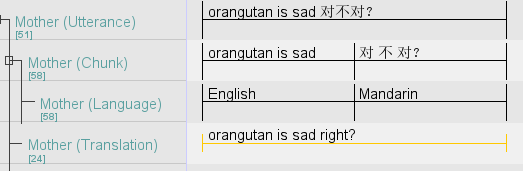
2. What’s an utterance?
Please refer to Shamala’s document entitled “A problem named utterance” for a full overview of how we define an utterance. Another way to think about it: an utterance is what can be considered a single thought process (that can also have interjections).
3. I can’t confidently tell where the utterance begins and ends.
The best way around this problem is to turn the audio rate down to 70, switch to segmentation mode, and press enter when you hear an utterance begin and end. Or you can use annotation mode and judge roughly by the shape of the sound wave where the utterance begins and ends. There is a caveat to using annotation mode though, because the sound wave is the combined the audio of everything occurring in the recording, using the sound wave to judge the beginning and end of the utterance might not always work. Segmentation mode is likely to cause less mistakes, but will definitely require practice.
If you thought you had reached the end of the utterance but it turned out you had not, there is a handy little tool in ELAN known as Merge Annotation. You can merge with the annotation before or after your selected annotation. Merge Annotation can be found by right clicking your selected annotation.
4. What shall I do with this brief inaudible section?
Just ignore the inaudible part and move on. Inaudible sections are useless to language programmers. However, if you feel like it may still be important for the context, transcribe it as ### in the Utterance and Chunk tiers, then tag it as “Vocal Sounds” in the language tier.
5. What shall I do with this long stretch in which none of the spoken words are audible?
Because the recording technology isn’t perfect, there will be sections where all conversation becomes extensively muffled. If this goes on for a significant period of time, say more than two minutes, select the section and add a comment in the “Comments” tab. Write “Muffled/Inaudible”.
6. The speakers were talking at the same time and I can’t quite make out what they’re saying. What should I do?
If there are instances of overlapping speech (i.e., speakers talking at the same time), try your best to transcribe one speaker at a time. That is, isolate your focus to transcribing one speaker instead of two speakers simultaneously. If that’s not possible at all, select the section and add a comment in the “Comments” tab. Write “Overlapping speech”.
7. Do we need to transcribe background speech/sounds?
There is no need to prioritise transcribing background speech/sounds if it is not part of the conversation of interest (e.g., the story book reading). Refer to question 4.
8. What shall I do when I am unsure of who said a particular thing?
If you can’t figure out who has said a particular thing, create a participant called “Unknown1” by following the instructions in “Transcribing dependent tiers” and set up tier properties as outlined in “A Guide to All Your Tiers” sections of this wiki.
9. Do utterances need to have proper capitalisation and punctuation when transcribed?
Utterances do not need capitalisation and punctuation when transcribed. There are a few exceptions that we allow. These include:
- Censoring personal information (e.g., BABYNAME, QUALTRICSID)
- Question marks (?) e.g., what is that?
- Ellipsis to indicate stuttering/interrupted speech (…) e.g. She told me that she t… took the taxi.
- Ellipsis can also be used to indicate a parent prompting children on words e.g.,
Mum: a pink um...Child: brella
- Ellipsis can also be used to indicate a parent prompting children on words e.g.,
- Tildes (~) to indicate long interjections (e.g., ohh~)
- Colons/equal/plus signs used within the special coding conventions e.g., :v:laughing (see “List of Special Codes” section of the wiki)
- Three pound signs (###) to indicate unintelligible/inaudible speech.
- Do note that ### is a standalone token and should not be with anything else, e.g.
:m:###or:si:###.
- Do note that ### is a standalone token and should not be with anything else, e.g.
- Apostrophes (‘) in contractions e.g., can’t, don’t, shouldn’t
- Hyphens (-) for word connecting forms e.g., jalan-jalan
10. What are the three tiers that always need to have annotated cells?
The Utterance, Chunk, and Language tiers. You will also have to translate the utterance on the Translation tier if you are transcribing non-English utterances. The translation can be a loose translation i.e., enough information for an outside English reader to understand what is going on.
11. How do we transcribe numbers?
Spell them out in the annotation e.g., “There are 3 apples” should be transcribed as there are three apples
For the Talk Together Study, if the numbers mentioned bare resemblance to the participant’s Talk Together Study/Qualtrics ID (5 digit number), transcribe it as QUALTRICSID
12. How do we spell mispronounced words?
For transcription, spell it as what you heard but add a comment in ELAN with the standardized/correct spelling of the word. Do not flag it as :v:u: if it’s obviously a mispronounced word.
13. How do we transcribe words which are being spelt out letter by letter?
At times, words might be spelt out letter by letter. In this case, each letter should be followed by an ellipsis. For example, if the word is ‘pea’, it should be transcribed as p... e... a... in the Utterance and Chunk tiers.
14. How should we transcribe a sibling’s speech?
There is a difference in transcription protocols and conventions when transcribing Baby and Adult speech. At times it might be difficult to decide how a sibling’s speech should be transcribed. In order to decide which conventions should be used, do refer to the Sibling tier section.
Back to table of contents
Privacy
15. Redacting Human Names
Please refer to the privacy matters section of the wiki. Contact a full time staff member should you have additional questions.
16. Which language should redacted names be tagged under?
All names should follow the language that the utterance is in.
Back to table of contents
Special codes and language-tagging
17. I know the language they are speaking but I don’t know what they’re saying.
Create a cell for the utterance and chunk, and label the language on the Language tier only. Leave the other tiers blank. Add a comment to alert your supervisor and the 2nd transcriber/checker.
18. I don’t know what language they are speaking.
Mark it on the Language Tier as #!#?. Leave the Utterance and Chunk tiers blank. Add a comment and inform your supervisor.
19. I want to mark the utterance as inaudible but I can’t even tell who said it.
Add a comment and write “Inaudible - speaker unknown”.
20. What’s the difference between discourse markers and languageless words?
Discourse markers are typically at the end of the sentence and are tagged with Red Dot language tag, whereas Languageless words may occur in any part of the sentence.
21. Is this a Languageless word, Discourse marker, or should i just tag it as part of a Language?
Below is a table (special thanks to Woon Fei Ting, Research Associate at BLIP Lab) which can help one to decide if a word should be tagged as “Languageless”, “Red Dot (discourse marker)” or another language.
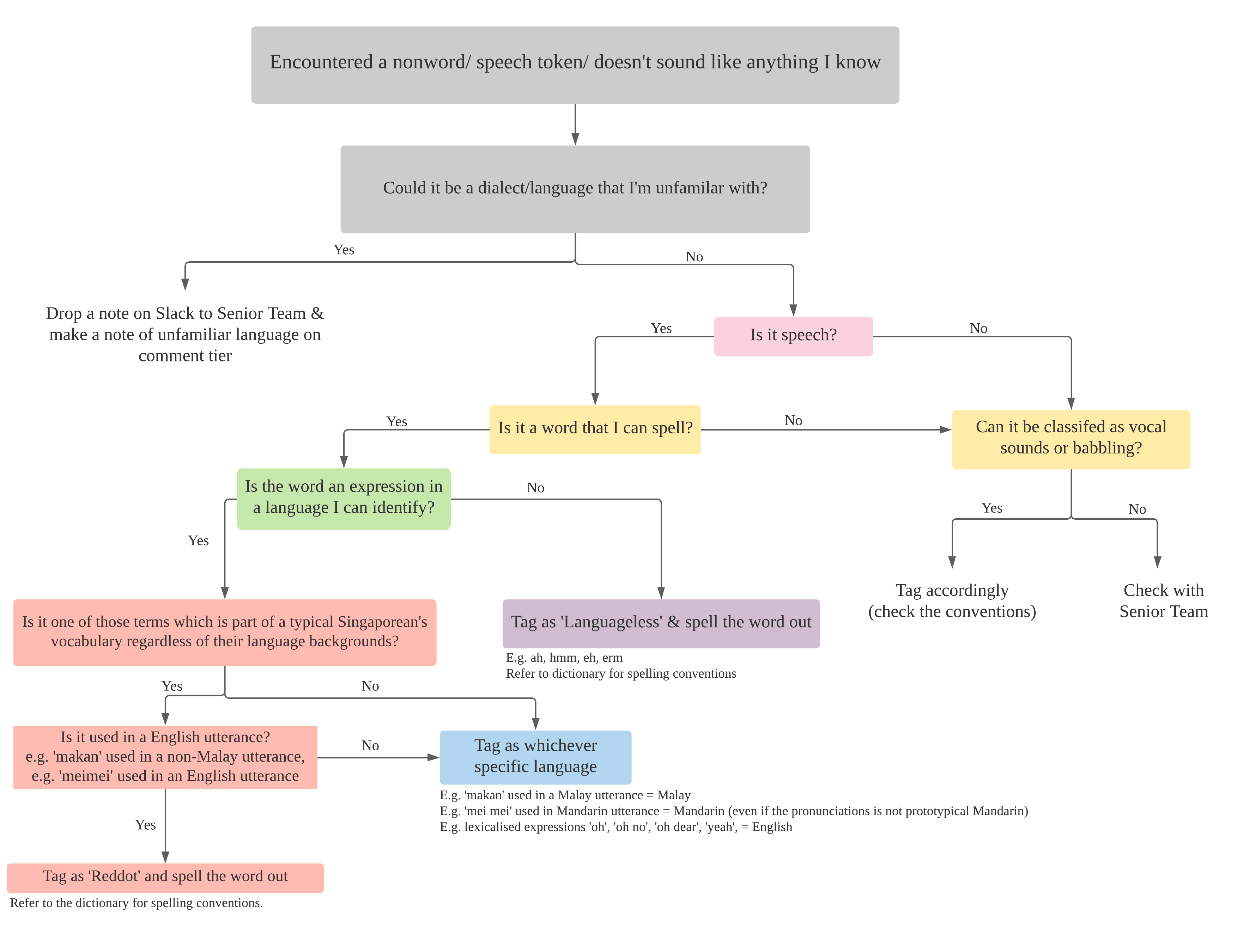
If it is spoken by a child/baby, do note that we do not use the “Languageless” tag at all in the Language tier.
22. Usage of non-English Bound Morphemes with English words.
Depends on the situation. As a rule, decide whether:
-
If it’s just for sound effect, tag it as the language in which the chunk and utterance is in.
-
If it does have a grammatical function, tag the root word as English and tag the morpheme as the relevant language, using the format for tagging bound morphemes to be found in “List of Special Characters”.

- Caveat: if it’s an English word with a bound morpheme in an otherwise non-English sentence, ask yourself if there is there another means to express this in the original language? If there is not, the English is the loanword and the whole thing should be tagged as part of the default language. If there is a means to express this in the original language, tag the English word as English and the rest of the Utterance as the relevant non-English language.
Example of first case: 
Example of second case: 
Back to table of contents
Language Specific: Malay [work in progress]
As of 23rd March 2022, current transcriptions have not adopted these conventions and protocols
Special thanks to Shaza Amran and Nur Sakinah (Research Assistants at BLIP) for providing the answers to the questions in this section
23. How do I transcribe Malay kinship terms if they are in Other Bahasa (e.g., Javanese) or Arabic?
Malay kinship terms used by Malay families, including loaned words from Other Bahasa (e.g., nyai for grandmother) and Arabic (e.g., ummi for mother), will be tagged as Malay.
Check the list of kinship terms used by Malay families in the BLIP dictionary for transcribers. Let us know if you think we’ve missed anything out.
If the term sounds like it might be a kinship term but you are not sure, please leave the annotation blank and tag it as
- #!#Bahasa in the Language tier OR
- #!#? (if you don’t know the language) in the Language tier. A checker will take note and make changes accordingly.
24. How do I transcribe shortened words or ‘bahasa pasar’ (informal language)?
Some sounds in daily or day-to-day language are omitted.
Vowel change: Words like aje (informal way of saying sahaja) (trans: ‘only’)
-
In spoken Malay, all formal and informal words ending with ‘a’ becomes ‘ə’ (e.g. aja/aje) and ‘i’ to ‘e’ (e.g. amik/amek)
-
Sometimes, the vowel ‘u’ is also pronounced as ‘o’ (e.g. lubang vs. lobang but kucing ≠ koceng)
Consonant change: Words like kecil (formal) and kecik (informal) (trans: small)
- In spoken Malay, both words can be used in informal settings, so if we follow the standard spelling, we would not know which one is spoken (kecik vs. kecil)
Contractions: Words like takde (tak de) (formal: tidak ada, trans: not have)
- In English, ‘gonna’ is kept as one word instead of being spelled as ‘going to’ or ‘gon na’
Proposed protocol:
-
/ʌ/ -> [ɛ] : transcribe final letter as ‘a’ if it sounds like ‘a’, ‘e’ if sounds like ‘e’ (e.g. aje)
-
/i/ -> [e] : C_C (‘e’ for shortened words, make a list for unshortened words) (e.g. abeh, kucing), V_C (spell ‘i’) (e.g. air)
-
/ɭ/ -> [ʔ] : spell ‘k’ when heard as k-like sound (e.g. kecik)
25. Some of the interjections are in Malay. How do I transcribe them?
Malay interjections such as ‘aduh’ (ouch), ‘aah’ (yes) and ‘amboi’ (wow) will be tagged as Malay when used in a Malay utterance. Otherwise, this may be listed under Red Dot (please refer to the BLIP dictionary for transcribers).
Sometimes, we use ‘lah’ as part of our Malay vocab, e.g. ‘lah, bukan payung rupanya’ (meaning ‘oh, it’s not an umbrella’, sometimes spelled as ‘ler’) or ‘baiklah, jom cari daun lain’ (meaning ‘okay, let’s find a different leaf’). These ‘lah’ will be tagged as Malay when used in a Malay utterance.
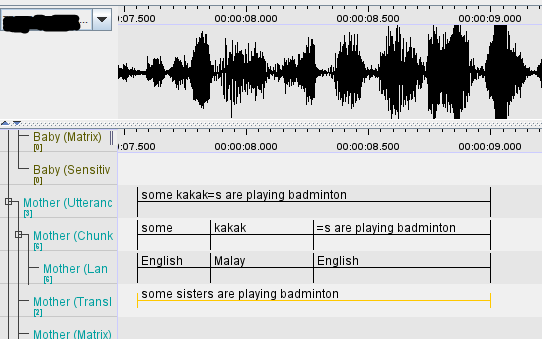
26. Language mixing within a word
At times, there might be the combining of English prefixes and/or suffixes with a Malay word
- e.g., ‘interestingnya’ - interesting + nya (translation: very)
- e.g., ‘kakaks’ - kakak (sister) + ‘s’ (plural)
For these cases, use the bound morpheme convention and separate at chunk level according to language of chunk
27. How do I transcribe reduplicated words?
In Malay, we use reduplication for pluralising and intensifying words
- Pluralising: kakak-kakak (sisters)
- Intensifying: cepat-cepat (quickly)
For these cases, transcribe as one word using a hyphen (-) between the reduplicated words.
Back to table of contents
Language Specific: Mandarin
Special thanks to Woon Fei Ting (Research Associate at BLIP) for providing the answers to the questions in this section
28. Are we required to put a space between the individual Chinese characters in an adjective? (eg 可爱 vs 可 爱)
No space because 可爱 is a word on its own with a different meaning from the individual characters. If the voice on the recording is trying to say something/someone is “cute” then no space please.
29. It seems that there should be spacing between characters depicting quantity in Chinese (eg 一 只). Does this apply to plurality as well (eg 我 们)?
一 and 只 should be separated because it is a number and a classifier. Classifiers have to appear for Mandarin constructions e.g. 个,条,件 and should remain separated from the number value. However, 我们 is a pronoun. This should not be separated because it is again a word on its own with a different meaning from the individual characters.
30. What is the convention when transcribing possessive markers in Chinese? (eg 他的 vs 他 的)
Like the number/classifier example above, possessive markers should be separated.
31. Is spacing needed between the characters for verbs in Chinese? (eg 看着 vs 看 着 / 长大 vs 长 大)
This one is tricky because Mandarin verbs have different forms. My idea is to separate when words do not have a different lexicalised meaning from the root verb e.g. separate for 看着, 看见,看到 - so for all these examples, the second character changes tense/usage but do not have a different lexicalised meaning that will require a separate dictionary entry BUT when we look at 看来, it does have a different lexicalised meaning from 看(i.e 看来 has its own dictionary entry separate from 看) so we do not separate the characters as it stands as a word on its own.
For 长大 , I would say do not separate for the same reason as 看来 as in 长大 is a lexicalised word. But if the it is 长帅,长壮,长高 - then we should separate because the meanings of these words cannot be teased apart from the root verb 长。Also these examples will not have separate dictionary entries that is separate from root verb.
I have been using this online dictionary as a guide.
32. Some Mandarin speakers may tend to shorten certain phrases, are there standardized characters for them?
These are the standardized characters to use for transcription, the actual phrase in the brackets should also be typed out in the annotation cell. Do refer to the BLIP Dictionary for transcribers for more of such examples.
- 做 莫 zuo4mo4(什么)
- 什莫 shen2mo4 (什么)
- 酱 jiang4(这样)
- 几 ji3 (e.g. 几 noisy only)
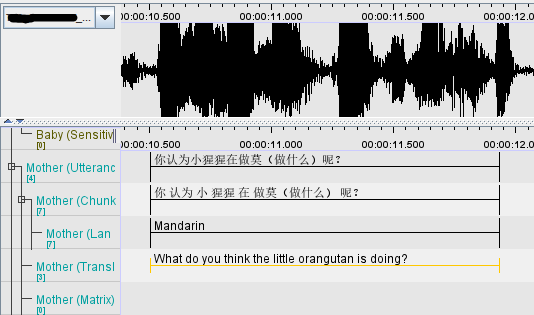
33. For reduplicated phrases such as 怕怕、圆圆、小小 etc., do we need to split them up in the Chunk tiers?
Reduplication is a common feature in Mandarin and when found in child-directed speech, it normally denotes diminutive forms. These should not be split up in the Chunk tiers.
2-word reduplication that are common for verbs and adjectives such as…
- 抱抱
- 怕怕
- 大大
- 小小
- 圆圆
- 短短
- 长长
This list is non-exhaustive. If you come across any other instances which you are unsure of, please do not hesitate to check with a full-time staff member who speaks Mandarin.
As for other forms of reduplication such as 看一看、对不对、好不好 (A-X-A form), each character should be split up in the Chunk tiers as shown in the example below:
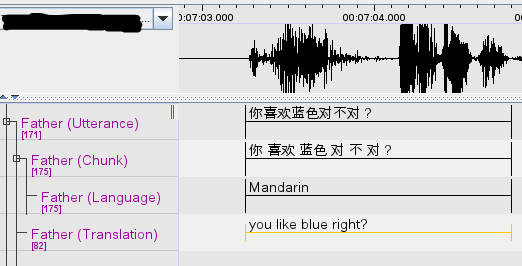
Back to table of contents
Language-Specific: Tamil
Special thanks to Vinitha Selvarajan (Research Assistant at BLIP) for providing the answers to the questions in this section
34. Do I transcribe in Standard Spoken Tamil (spoken variety) or Literary Tamil (written variety)?
Always transcribe whichever Tamil variety you hear from the speaker and don’t change any spoken forms to the written variety.
35. How do I tell what variety is being used?
Native speakers tend to use the spoken variety (“Pechu Thamizh”/பேச்சு தமிழ்) in most non-formal contexts and the written variety in formal contexts. For example, Standard Spoken Tamil may be used in casual talk amongst friends and family while Literary Tamil may be used in classrooms or by newsreaders. While most native speakers can easily discern which variety is being used, knowing the context might help you make that decision as well. Do also note that speakers can switch between the varieties and the transcription should be consistent with these switches should they occur.
36. How do I transcribe Spoken Tamil?
Written Tamil has standard spelling. Most of these spelling conventions accurately represents spoken Tamil. However, sometimes these conventions are not very representative of how spoken Tamil sounds. Hence, we might spell those words differently to stay true to the phonology of the variety. We have included some spelling conventions for transcribing spoken Tamil here:
- If the word you are transcribing is a pronoun form ending with -ங்கள் in the literary variety, it should be transcribed as ending with -ங்க in spoken form.
| Written form spelling | Spoken form spelling |
|---|---|
| நாங்கள் | நாங்க |
| நீங்கள் | நீங்க |
| அவர்கள் | அவங்க |
| இவர்கள் | இவங்க |
| எங்கள்* | எங்க* |
- ஆனால் (meaning: but or however) can be spelled as ஆனா in spoken form.
| Written form spelling | Spoken form spelling |
|---|---|
| ஆனால் | ஆனா |
- Words about place and location of an object or the speaker such as, இங்கே, அங்கே and எங்கே should be transcribed the same way in spoken Tamil as it would be in the written variety. Even though the spoken variety of these word may sound a little different and you might want to transcribe it ending with -க instead of -கே, we will keep this spelling convention to avoid confusion. For example, if we transcribe எங்கே (written) as எங்க (spoken), it might be tokenized as the spoken variety form of the word எங்கள்* mentioned above.
| Written form spelling | Spoken form spelling |
|---|---|
| இங்கே | இங்கே (remains the same) |
| அங்கே | அங்கே (remains the same) |
| எங்கே | எங்கே (remains the same) |
- Prepositions should also be transcribed the same way in spoken Tamil as it would be in the written variety.
| Written form spelling | Spoken form spelling |
|---|---|
| மேலே | மேலே (remains the same) |
| கீழே | கீழே (remains the same) |
| உள்ளே | உள்ளே (remains the same) |
| வெளியே | வெளியே (remains the same) |
37. Do I tag “ah”/ “ஆ” as Tamil or Languageless?
This depends on the context. If for example the ‘ah’ occurring in the speech is meant to show surprise like “Ah, there you are!”, then it should be tagged as Languageless. However native Tamil speakers use “ஆ” which is short for ‘ஆம்’ which means ‘yes’. So if the ‘ah/ஆ’ is being used to mean ‘yes’ or to show agreement and is being used by a native Tamil speaker, it should be tagged as Tamil.
Back to table of contents
ELAN specific questions
38. When do I use annotation mode and when do I use segmentation mode?
It is better to use segmentation mode for accuracy’s sake. However, one situation in which annotation mode will definitely be easier is when there is a large amount of tiers, in which there are many participants and the participants frequently switch between languages. Honestly, you can toggle between both as far as is convenient for you, but as a rule, if you have upwards of three participants, at least two of which use two or more languages and show a high amount of overlap in their speech, annotation mode will probably be easier for you.
39. What should I do with tiers that I don’t use from the template file?
Ignore them and DO NOT delete them. If you don’t need to use them, don’t annotate on them. If they are getting in your way, right click the tier panel and hide them.
Back to table of contents