Transcribing tasks from the Talk Together Study (TTS)
Last updated: Sept 25th 2023
This page is our protocol how to approach transcribing data from the various Talk Together Study activities.
Please refer to the previous pages for specific guidance on transcription conventions, language tags, the tiers needed, or the ELAN template.
The playlist of our video tutorials geared towards transcribing data from the Talk Together Study can be found here. However, please cross-reference the wiki for the most up-to-date protocol. Any changes to the protocol since the creation of the videos have been noted in the video description.
Additionally, watch our video regarding things to keep in mind during the transcription process.
Do not hesitate to contact a full-time staff member should you have questions.
Contents
- Transcribing Voicemail Game Picture Cards Recordings
- Transcribing Voicemail Game Talk Prompts Recordings
- Transcribing Voicemail Game Green Grass Park Recordings
- Transcribing Video Call Storytime Phase/Timepoint 1 Recordings
- Transcribing Video Call Storytime Phase/Timepoint 2 Recordings
- Transcribing Video Call Storytime Phase/Timepoint 3 Recordings
Transcribing Voicemail Game Picture Cards Recordings
For a video demonstration of transcribing a picture card recording, please watch this video from our playlist.
As part of the Voicemail Game in this study, participants will record an audio recording of their responses to three different Voicemail Game activities in English and also in their other preferred language (Mandarin, Malay, or Tamil). The first activity of the Voicemail Game is the Picture Cards activity. We may also refer to this as the Vowel Triangle activity.
The picture cards include a picture and an associated “target” word. Participants will read the individual words one-by-one in English and their other preferred language language. The recording should only contain one adult speaker.
Visit this page to see all the picture cards sorted by language.
-
Import the audio file (.wav) and the template file (.etf) into ELAN. Refer to the “Transcription Template” section of the wiki on instructions on how to handle the template subsequent to importing it.
-
Go to “File” and click “Save” or “Save As” like a normal document. The file should be named according to the file naming conventions outlined on the wiki. You can also set an automatic backup of the file by going to “File” > “Automatic Backup”. Choose a time interval between 1 to 30 minutes that suits your preference. Note: the backup file will be saved with the extension
*.eaf.001. -
In order to see the hierarchical relationship between the dependent tiers, right click on the tier sidebar > Sort Tiers > Sort by Hierarchy.
-
Listen to the audio file in full before you begin transcribing. Mentally note what languages are being spoken. Note any muffled parts or parts where all speech become indecipherable. Information on how to deal with these parts can be found under Frequently Asked Questions (FAQ).
-
Edit the tier attributes to replace placeholder participant codes with accurate participant ID codes for all the participants present in the recording. This should be done on all the present participant’s primary and secondary tiers.(e.g. if the participant ID is
P1234TTand the mother is the only speaker in this recording, the Mother codeMPXXXXTTshould be edited toMP1234TTon all the Mother primary and secondary tiers). DO NOT DELETE UNUSED TIERS. Right click on the tier panel and hide them if they are getting in your way -
Adjust the vertical zoom (right click on the waveform > Vertical Zoom > adjust the %) and horizontal zoom (adjust the slider at the bottom right of the ELAN screen) to help you see the waveform clearly.
- Put on your headphones and begin transcribing the audio file.
- Isolate and annotate the individual target words on the
Utterance,Chunk,Language, and relevant Target_Language (i.e.,Target_EL,Target_ML, etc.) tiers. Additionally, translate any non-English words on theTranslationtier. - The Target_Language tiers (English
Target_EL, MandarinTarget_CL, MalayTarget_ML) have assigned controlled vocabularies that contain all the picture cards words. The TamilTarget_TLtier requires manual input (i.e., typing) as the ELAN software does not allow for Tamil script in controlled vocabularies (yet).
- Isolate and annotate the individual target words on the
-
Ensure you mark out the start and end of the Picture Cards recording on the
ActivityMarkerstier. Do this even if the recording only contains one word, or if the recording for the Picture Cards activity is contained within a larger recording that also includes the other Voicemail Game activities (Picture Prompts/Green Grass Park).:marker:start:ads_voweltri_[language]should be used to mark the start of the picture cards activity (e.g.,:marker:start:ads_voweltri_Tamilwould be used to demarcate the start of the Tamil picture cards recording).:marker:end:ads_voweltri_[language]should be used to mark the end of the picture cards activity (e.g.,:marker:start:ads_voweltri_Tamilwould be used to demarcate the end of the Tamil picture cards recording).- Watch our video here or the read the activity markers section in our tier guide in this wiki should you need more guidance on how the ActivityMarkers tier works.
Back to table of contents
Transcribing Voicemail Game Talk Prompts Recordings
For a video demonstration of transcribing a talk prompts recording, please watch this video from our playlist.
As part of the Voicemail Game in this study, participants will record an audio recording of their responses to three different Voicemail Game activities in English and also in their other preferred language (Mandarin, Malay, or Tamil. The second activity of the Voicemail Game is the Talk Prompts activity.
Participants are given a set of eight (8) topics in English and in their other preferred language. They select one topic in each language, and record their response to the chosen topic prompt in the respective languages. The recording should only contain one adult speaker.
Visit this page to see all the topic prompts sorted by language.
-
Import the audio file (.wav) and the template file (.etf) into ELAN. Refer to the “Transcription Template” section of the wiki on instructions on how to handle the template subsequent to importing it.
-
Go to “File” and click “Save” or “Save As” like a normal document. The file should be named according to the file naming conventions outlined on the wiki. You can also set an automatic backup of the file by going to “File” > “Automatic Backup”. Choose a time interval between 1 to 30 minutes that suits your preference. Note: the backup file will be saved with the extension
*.eaf.001. -
In order to see the hierarchical relationship between the dependent tiers, right click on the tier sidebar > Sort Tiers > Sort by Hierarchy.
-
Listen to the audio file in full before you begin transcribing. Mentally note what languages are being spoken. Note any muffled parts or parts where all speech become indecipherable. Information on how to deal with these parts can be found under Frequently Asked Questions (FAQ).
-
Edit the tier attributes to replace placeholder participant codes with accurate participant ID codes for all the participants present in the recording. This should be done on all the present participant’s primary and secondary tiers.(e.g. if the participant ID is
P1234TTand the mother is the only speaker in this recording, the Mother codeMPXXXXTTshould be edited toMP1234TTon all the Mother primary and secondary tiers). DO NOT DELETE UNUSED TIERS. Right click on the tier panel and hide them if they are getting in your way -
Adjust the vertical zoom (right click on the waveform > Vertical Zoom > adjust the %) and horizontal zoom (adjust the slider at the bottom right of the ELAN screen) to help you see the waveform clearly.
-
Put on your headphones and begin transcribing the audio file. Utilise the
Utterance,Chunk, andLanguagetier. For recordings of responses to prompts in the preferred languages (Mandarin, Malay, Tamil), utilise theTranslationtier as well. -
Ensure you mark out the start and end of the Talk Prompts recording on the
ActivityMarkerstier. Do this even if the recording for the Talk Prompts activity is contained within a larger recording that also includes the other activities (Picture Cards/Green Grass Park).:marker:start:ads_prompts_[language]should be used to mark the start of the talk prompts activity (e.g.,:marker:start:ads_prompts_Engwould be used to demarcate the start of the English talk prompts recording).:marker:end:ads_prompts_[language]should be used to mark the end of the talk prompts activity (e.g.,:marker:start:ads_voweltri_Engwould be used to demarcate the end of the Eng talk prompts recording).- Watch our video here or the read the activity markers section in our tier guide in this wiki should you need more guidance on how the ActivityMarkers tier works.
Back to table of contents
Transcribing Voicemail Game Green Grass Park Recordings
For a video demonstration of transcribing a green grass park recording from the voicemail game, please watch this video from our playlist.
As part of the Voicemail Game in this study, participants will record an audio recording of their responses to three different Voicemail Game activities in English and also in their other preferred language (Mandarin, Malay, or Tamil. The third and last activity of the Voicemail Game is the Green Grass Park activity.
Participants are given a picture prompt called “Green Grass Park”. There are three version of the picture; a Mandarin version, a Malay version, and a Tamil Version. All three versions also have English on them. The Mandarin/Malay/Tamil words on the image are “target” words. Participants select one version and record themselves describing what they see in the picture. They are given the option to use whichever presented language they are most comfortable with, or to mix them. The recording should only contain one adult speaker.
Visit this page to see all the Green Grass Park pictures sorted by language (click the images on the page to enlarge them).
-
Have the Green Grass Park image open. This is so you can reference it to identify the participant’s use of any Mandarin/Malay/Tamil target words in their recording.
-
Import the audio file (.wav) and the template file (.etf) into ELAN. Refer to the “Transcription Template” section of the wiki on instructions on how to handle the template subsequent to importing it.
-
In order to see the hierarchical relationship between the dependent tiers, right click on the tier sidebar > Sort Tiers > Sort by Hierarchy.
-
Go to “File” and click “Save” or “Save As” like a normal document. The file should be named according to the file naming conventions outlined on the wiki. You can also set an automatic backup of the file by going to “File” > “Automatic Backup”. Choose a time interval between 1 to 30 minutes that suits your preference. Note: the backup file will be saved with the extension
*.eaf.001. -
Listen to the audio file in full before you begin transcribing. Mentally note what languages are being spoken. Note any muffled parts or parts where all speech become indecipherable. Information on how to deal with these parts can be found under Frequently Asked Questions (FAQ).
-
Edit the tier attributes to replace placeholder participant codes with accurate participant ID codes for all the participants present in the recording. This should be done on all the present participant’s primary and secondary tiers.(e.g. if the participant ID is
P1234TTand the mother is the only speaker in this recording, the Mother codeMPXXXXTTshould be edited toMP1234TTon all the Mother primary and secondary tiers). DO NOT DELETE UNUSED TIERS. Right click on the tier panel and hide them if they are getting in your way -
Adjust the vertical zoom (right click on the waveform > Vertical Zoom > adjust the %) and horizontal zoom (adjust the slider at the bottom right of the ELAN screen) to help you see the waveform clearly.
- Put on your headphones and begin transcribing the audio file.
- Transcribe utterances on the
Utterance,Chunk, andLanguagetiers. Also use theTranslationtier should you need to translate non-English utterances into English. - Isolate and transcribe any instances of individual target words on the relevant
Target_Language(i.e.,Target_CL,Target_ML, orTarget_TL) tiers. - The Target_Language tiers (Mandarin
Target_CL, MalayTarget_ML) have assigned controlled vocabularies that contain all the Green Grass Park Mandarin/Malay Green Grass Park target words. The TamilTarget_TLtier requires manual input (i.e., typing) as the ELAN software does not allow for Tamil script in controlled vocabularies (yet).
- Transcribe utterances on the
-
Ensure you mark out the start and end of the Green Grass Park recording on the
ActivityMarkerstier. Do this even if the recording for the Green Grass Park activity is contained within a larger recording that also includes the other activities (Picture Cards/Talk Prompts).:marker:start:ads_ggpshould be used to mark the start of the Voicemail Game Green Grass Park activity.:marker:end:ads_ggpshould be used to mark the end of the Voicemail Game Green Grass Park activity- Watch our video here or the read the activity markers section in our tier guide in this wiki should you need more guidance on how the ActivityMarkers tier works.
Back to table of contents
Transcribing Video Call Storytime Phase 1 Recordings
The Video Call Storytime (VCST) activity in the Talk Together Study is a recording of an interaction between a parent and child over a video call (Zoom). The Phase/Timepoint 1 VCST recording includes:
- The parent reading “The Little Orangutan: What a Scary Storm” book to their child. The researcher shares this book on screen.
The VCST will usually include one Parent (Father or Mother), one Baby, and one Researcher. There may be instances where another person’s voice may appear in the recording (e.g., a sibling of the baby, another family member, etc.)
- Watch the VIDEO recording file in full before you begin transcribing.
- Familiarize yourself with the participants’ voices and any contextual information.
- Note how many participants there are. Identify the participant by their relationship to the baby.
- Note what languages are being spoken.
- Note down the timepoints when the story reading segment starts and ends for ActivityMarker purposes
- the start of the story segment is the very start of the recording, including researcher instruction/speech
- the end of the story segment is usually when the parent/child says ‘the end’ or finishes recapping the story or finishes talking about the orangutan holding pencils on the last page of the book. The ending marker should be placed right before the researcher comes back into the recording and says something along the lines of “Thank you! You and your child looked like you were having so much fun….” If you’re unsure, ask a full-time staff member.
- Note any muffled parts or parts where all speech become indecipherable. Information on how to deal with these parts can be found under Frequently Asked Questions (FAQ).
-
Import the associated AUDIO (.wav) file and the template file (.etf) into ELAN. Refer to the “Transcription Template” section of the wiki on instructions on how to handle the template subsequent to importing it.
-
a) Go to “File” and click “Save” or “Save As” like a normal document. The file should be named according to the file naming conventions outlined on the wiki. You can also set an automatic backup of the file by going to “File” > “Automatic Backup”. Choose a time interval between 1 to 30 minutes that suits your preference. Note: the backup file will be saved with the extension
*.eaf.001.b) Update the transcription log - namely AudioFileName (Column B), TranscribedFileName (Column C), Project (Column D, in this case would be TTS), Audio Length (Column E), Language(s) spoken in the recording (Column G), Transcriber 1 (Column H, which would be your name), Date issued (Column I). It will also help to write down anything of note (e.g., audio dropping at any point, the length of an activity) into the Comments by Transcriber (Column M).
-
Return to ELAN. In order to see the hierarchical relationship between the dependent tiers in ELAN, right click on the tier sidebar > Sort Tiers > Sort by Hierarchy.
-
Edit the tier attributes to replace placeholder participant codes with accurate participant ID codes for all the participants present in the recording. This should be done on all the present participant’s primary and secondary tiers.(e.g. the participant ID is
P1234TTand the mother, baby, and researcher (R099) are present in this recording. The Mother codeMPXXXXTTshould be edited toMP1234TTon all the Mother primary and secondary tiers. The Baby codePXXXXTTshould be edited toP1234TTon all the Baby primary and secondary tiers. The Researcher codeR00XPxxxxTTshould be edited toR099P1234TTon all the Researcher primary and secondary tiers). DO NOT DELETE UNUSED TIERS. Right click on the tier panel and hide them if they are getting in your way -
Adjust the vertical zoom (right click on the waveform > Vertical Zoom > adjust the %) and horizontal zoom (adjust the slider at the bottom right of the ELAN screen) to help you see the waveform clearly.
- Put on your headphones and begin transcribing the story reading segment of the audio file.
- Transcribe utterances on the
Utterance,Chunk, andLanguagetiers. Use theTranslationtier should you need to translate any non-English utterances into English. - Isolate instances (e.g., mention of the baby’s name) that need redacting on the
Sensitive_Maskingtier. Live demo on how to use the Sensitive_Masking tier here. - What counts as an utterance? Read “A Problem Named Utterance” by Dr. Shamala Sundaray, which can be found here
- Utterances directed to the child and researcher should be separate. For instance, the parent may follow up an utterance to the child with a directive to the researcher, e.g., look at the monkey okay next page what is this. A part of the utterance is instructions directed to the researcher to flip the page during the storybook sharing task. Hence, it should be transcribed as separate utterances: look at the monkey, okay next page, what is this. In general, utterances directed to two different people should be considered as separate utterances. In some cases, prosodic information in the audio file may offer additional information on how to segment the utterance.
- Transcribe utterances on the
- Decide how to transcribe speech unrelated to storybook reading.
- There is a difference in transcription protocols and conventions when transcribing utterances related or unrelated to the storybook reading.
- As a general rule of thumb, we wish to transcribe speech that is observed during the story reading segment to understand how parents engage their children in a shared storybook reading exercise. During the story reading segment, there may be speech that is not related to the storybook reading. Examples:
- questions or instructions to researchers (e.g., is the page supposed to turn?, next page),
- requests to pause the task (e.g., sorry can we pause?),
- talks to another person (e.g., Mother turning around to talk to Father that came into the room)
- For the above scenarios, if the parent remains on screen and does not start a completely new task, speech should be transcribed as per normal.
- On the other hand, if the parent leaves the screen or starts a completely new task unrelated to story reading, we will partially transcribe the speech as outlined in Step 9 below.
- In order to decide which conventions should be used, this decision table should be used. If you are still unsure, please check in with any team members for further clarification.
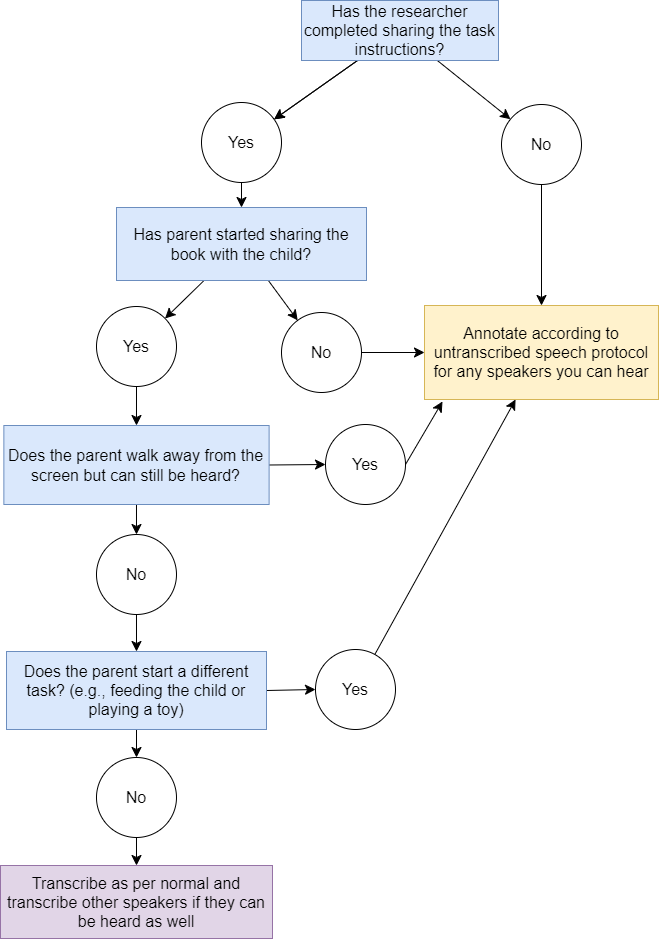
- Partially transcribe speech unrelated to storybook reading.
- For the portions before the start and after the end of story reading segment of the audio file, if any speaker is talking, mark the onsets and offsets of each utterance.
- As we only wish to transcribe speech during story reading segment, utterances that occur before the start of story reading and utterances that occur after the end of story reading should be labelled but do not need to be fully transcribed.
- If the utterance only contains speech and vocal sounds, demarcate the onset and offset of the utterance. Type
*untranscribed_speech*(with the asterisks) in the Utterance and Chunk tiers. Then, use the Vocal Sounds tag in the Language tier. There is no need to demarcate the onsets and offsets of different languages or vocal sounds for each utterance. If the Baby makes noises/speaks, follow the same procedure in the Utterance and Chunk tiers, and the Language tag is Vocal Sounds as well. This is the only time Vocal Sounds can be used in the Baby (Language) tier.

- If the utterance only contains non-vocal sounds, it should be labelled with the appropriate tags. Example, if there is clapping,
:s:clappingshould be enclosed in the Utterance and Chunk tiers, while Non Vocal Sounds should be used in the Language tier. Note that the chime sound that plays when the orangutan storybook pages turn should not be transcribed. Mouse clicks should not be transcribed either. Read our section on non-vocal sounds here should you need additional guidance on what non-vocal sounds should be labelled.

- If the utterance contains both non-vocal sounds and speech, the onset and offset of speech and non vocal sounds should be demarcated accordingly. If the chime sound that plays when the orangutan storybook pages turn or mouse clicking sounds happen in between untranscribed speech, there is no need to demarcate them.
- If you hear names or items to be redacted, isolate these instances the in SENSITIVE_MASKING tiers. Refer to this site to see what should be redacted.
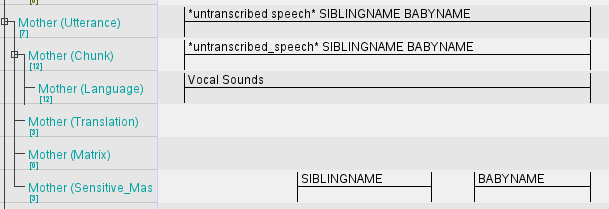
- If more than one Sensitive_Masking tag appears in an utterance, they should be added by order of which they appear. For example, if the Mother says the sibling’s name followed by some words and then the baby’s name, you should transcribe it as:
*untranscribed_speech* SIBLINGNAME BABYNAMEin the Utterance and Chunk tier. Then isolate the instances of each name in the SENSITIVE_MASKING tier of the Mother.
- If more than one Sensitive_Masking tag appears in an utterance, they should be added by order of which they appear. For example, if the Mother says the sibling’s name followed by some words and then the baby’s name, you should transcribe it as:
- IMPORTANT: If you are unsure whether to redact an audio region, please consult the team for a second opinion. It’s important for us to ascertain carefully if an audio region should be redacted or not to protect the privacy of our participants.
NOTE: We recommend future researchers to do Steps 8 and 9 while transcribing the audio file. These steps were done post-hoc when transcribing the Talk Together Study audio files and added into the transcription protocol after. Since July 2023, these steps have been fully integrated into the BLIP lab’s transcription workflow (see Talk-a-thon VCST protocol).
-
Ensure you mark out the start and end of the story reading segment in the recording on the
ActivityMarkerstier. Follow the guidelines in step 1 to get an understanding of where each activity starts and ends. Do consult a full-time staff member should you have any questions.:marker:start:cds_bookshould be used to mark the start of the Story Reading segment.:marker:end:cds_bookshould be used to mark the end of the Story Reading Segment.- Watch our video here or the read the activity markers section in our tier guide in this wiki should you need more guidance on how the ActivityMarkers tier works.
-
Update the transcription log to note your transcription progress on a given file.
a) If you’re still working on the file, note “ongoing” in Column J (actual trans. hrs) and add the date and amount of audio transcribed in the 1st or 2nd listen column (Column K and L, respectively).
b) If you have finished transcribing a file alert a full-time staff member, update Column J (actual trans. hrs) with the number of hours it took you to complete the transcription, and write the dates of completion of each listen in Column K and L.
For more information about each column in the Transcription Log, please refer to this page in the wiki.
Back to table of contents
Transcribing Video Call Storytime Phase 2 Recordings
The Video Call Storytime (VCST) activity in the Talk Together Study is a recording of an interaction between a parent and child over a video call (Zoom). The Phase/Timepoint 2 VCST recordings includes:
- The parent describing the “Green Grass Park” picture prompt to their child. The parent has a maximum of 5 minutes but can choose to end this activity earlier. The Green Grass Park pictures for the VCST are different from the Voicemail game version, and the transcriber does not need to isolate and transcribe any target words.
- The parent reading “The Little Orangutan: What a Scary Storm” book to their child
The VCST will usually include one Parent (Father or Mother), one Baby, and one Researcher. There may be instances where another person’s voice may appear in the recording (e.g., a sibling of the baby, another family member, etc.)
- Watch the VIDEO recording file in full before you begin transcribing.
- Familiarize yourself with the participants’ voices and any contextual information.
- Note how many participants there are. Identify the participant by their relationship to the baby.
- Note what languages are being spoken.
- Note down the timepoints when the Green Grass Park (GGP) segment starts and ends for ActivityMarker purposes
- The start of the GGP segment is the very start of the recording, including researcher instruction/speech
- The end of the GGP segment is usually when the researcher says something along the lines of “Time’s up! That was great” (meaning the parent reacher the 5 minutes), or if the parent says something along the lines of “Next. I’m ready to move on to the next activity”.
- Note down the timepoints when the story reading segment starts and ends for ActivityMarker purposes
- The start of the story segment is when the researcher says something along the lines of “I will now switch off my camera. Just remember, once you are ready to go to the next page, you can tell me ‘Next!’ Are you ready? Okay let’s begin”. Ensure you include this researcher instruction/speech within the starting marker.
- The end of the story segment is usually when the parent/child says ‘the end’ or finish recapping the story or finish talking about the orangutan holding pencils on the last page of the book. The ending marker should be placed right before the researcher comes back into the recording and says something along the lines of “Thank you! You and your child looked like you were having so much fun….” If you’re unsure, ask a full-time staff member.
- Note any muffled parts or parts where all speech become indecipherable. Information on how to deal with these parts can be found under Frequently Asked Questions (FAQ).
-
Import the associated AUDIO (.wav) file and the template file (.etf) into ELAN. Refer to the “Transcription Template” section of the wiki on instructions on how to handle the template subsequent to importing it.
-
a) Go to “File” and click “Save” or “Save As” like a normal document. The file should be named according to the file naming conventions outlined on the wiki. You can also set an automatic backup of the file by going to “File” > “Automatic Backup”. Choose a time interval between 1 to 30 minutes that suits your preference. Note: the backup file will be saved with the extension
*.eaf.001.b) Update the transcription log - namely AudioFileName (Column B), TranscribedFileName (Column C), Project (Column D, in this case would be TTS), Audio Length (Column E), Language(s) spoken in the recording (Column G), Transcriber 1 (Column H, which would be your name), Date issued (Column I). It will also help to write down anything of note (e.g., audio dropping at any point, the length of an activity) into the Comments by Transcriber (Column M).
-
Return to ELAN. In order to see the hierarchical relationship between the dependent tiers, right click on the tier sidebar > Sort Tiers > Sort by Hierarchy.
-
Edit the tier attributes to replace placeholder participant codes with accurate participant ID codes for all the participants present in the recording. This should be done on all the present participant’s primary and secondary tiers.(e.g. the participant ID is
P1234TTand the mother, baby, and researcher (R099) are present in this recording. The Mother codeMPXXXXTTshould be edited toMP1234TTon all the Mother primary and secondary tiers. The Baby codePXXXXTTshould be edited toP1234TTon all the Baby primary and secondary tiers. The Researcher codeR00XPxxxxTTshould be edited toR099P1234TTon all the Researcher primary and secondary tiers). DO NOT DELETE UNUSED TIERS. Right click on the tier panel and hide them if they are getting in your way -
Adjust the vertical zoom (right click on the waveform > Vertical Zoom > adjust the %) and horizontal zoom (adjust the slider at the bottom right of the ELAN screen) to help you see the waveform clearly.
- Put on your headphones and begin transcribing the story reading segment and GGP segment of the audio file.
- Transcribe utterances on the
Utterance,Chunk, andLanguagetiers. Use theTranslationtier if you need to translate any non-English utterances into English. - Isolate instances (e.g., mention of the baby’s name) that need redacting on the
Sensitive_Maskingtier. Live demo on how to use the Sensitive_Masking tier here. - What counts as an utterance? Read “A Problem Named Utterance” by Dr. Shamala Sundaray, which can be found here
- Utterances directed to the child and researcher should be separate. For instance, the parent may follow up an utterance to the child with a directive to the researcher, e.g., look at the monkey okay next page what is this. A part of the utterance is instructions directed to the researcher to flip the page during the storybook sharing task. Hence, it should be transcribed as separate utterances: look at the monkey, okay next page, what is this. In general, utterances directed to two different people should be considered as separate utterances. In some cases, prosodic information in the audio file may offer additional information on how to segment the utterance.
- Transcribe utterances on the
- Decide how to transcribe speech unrelated to storybook reading and unrelated to GGP segments.
- There is a difference in transcription protocols and conventions when transcribing utterances related or unrelated to the activities in the audio recording (in this case, storybook reading and GGP).
- As a general rule of thumb, we wish to transcribe speech that is observed during the story reading and GGP segments to understand how parents engage their children in these shared activities. During these activities, there may be speech that is not related to the activities. Examples:
- questions or instructions to researchers (e.g., is the page supposed to turn?, next page),
- requests to pause the task (e.g., sorry can we pause?),
- talks to another person (e.g., Mother turning around to talk to Father that came into the room)
- For the above scenarios, if the parent remains on screen and does not start a completely new task, speech should be transcribed as per normal.
- On the other hand, if the parent leaves the screen or starts a completely new task unrelated to story reading or GGP, we will partially transcribe the speech as outlined in Step 9 below.
- In order to decide which conventions should be used, this decision table should be used. If you are still unsure, please check in with any team members for further clarification.
- Partially transcribe speech unrelated to storybook reading or GGP segements.
- For the portions before the start and after the end of story reading and GGP segments of the audio file, if any speaker is talking, mark the onsets and offsets of each utterance.
- As we only wish to transcribe speech during story reading or GGP segments, utterances that occur before the start of story reading (and GGP) and utterances that occur after the end of story reading (and GGP) should be labelled but do not need to be fully transcribed.
- Utterances that occur during the transition of GGP to storybook reading should also be labelled and do not need to be fully transcribed.
- If the utterance only contains speech and vocal sounds, demarcate the onset and offset of the utterance. Type
*untranscribed_speech*(with the asterisks) in the Utterance and Chunk tiers. Then, use the Vocal Sounds tag in the Language tier. There is no need to demarcate the onsets and offsets of different languages or vocal sounds for each utterance. If the Baby makes noises/speaks, follow the same procedure in the Utterance and Chunk tiers, and the Language tag is Vocal Sounds as well. This is the only time Vocal Sounds can be used in the Baby (Language) tier.
- If the utterance only contains non-vocal sounds, it should be labelled with the appropriate tags. Example, if there is clapping,
:s:clappingshould be enclosed in the Utterance and Chunk tiers, while Non Vocal Sounds should be used in the Language tier. Note that the chime sound that plays when the orangutan storybook pages turn should not be transcribed. Mouse clicks should not be transcribed either. Read our section on non-vocal sounds here should you need additional guidance on what non-vocal sounds should be labelled.
- If the utterance contains both non-vocal sounds and speech, the onset and offset of speech and non vocal sounds should be demarcated accordingly. If the chime sound that plays when the orangutan storybook pages turn or mouse clicking sounds happen in between untranscribed speech, there is no need to demarcate them.
- If you hear names or items to be redacted, isolate these instances the in SENSITIVE_MASKING tiers. Refer to this site to see what should be redacted.
- If more than one Sensitive_masking tag appears in an utterance, they should be added by order of which they appear. For example, if the Mother says the sibling’s name followed by some words and then the baby’s name, you should transcribe it as:
*untranscribed_speech* SIBLINGNAME BABYNAMEin the Utterance and Chunk tier. Then isolate the instances of each name in the SENSITIVE_MASKING tier of the Mother.
- If more than one Sensitive_masking tag appears in an utterance, they should be added by order of which they appear. For example, if the Mother says the sibling’s name followed by some words and then the baby’s name, you should transcribe it as:
- IMPORTANT: If you are unsure whether to redact an audio region, please consult the team for a second opinion. It’s important for us to ascertain carefully if an audio region should be redacted or not to protect the privacy of our participants.
NOTE: We recommend future researchers to do Steps 8 and 9 while transcribing the audio file. These steps were done post-hoc when transcribing the Talk Together Study audio files and added into the protocol after. Since July 2023, these steps have been fully integrated into the BLIP lab’s transcription workflow (see Talkathon VCST protocol).
-
Ensure you mark out the start and end of the GGP segment and story reading segment in the recording on the
ActivityMarkerstier. Follow the guidelines in step 1 to get an understanding of where each activity starts and ends. Do consult a full-time staff member should you have any questions.:marker:start:cds_ggpshould be used to mark the start of the VCST Green Grass Park segment.:marker:end:cds_ggpshould be used to mark the end of the VCST Green Grass Park segment.:marker:start:cds_bookshould be used to mark the start of the Story Reading segment.:marker:end:cds_bookshould be used to mark the end of the Story Reading Segment.- Watch our video here or the read the activity markers section in our tier guide in this wiki should you need more guidance on how the ActivityMarkers tier works.
-
Update the transcription log to note your transcription progress on a given file.
a) If you’re still working on the file, note “ongoing” in Column J (actual trans. hrs) and add the date and amount of audio transcribed in the 1st or 2nd listen column (Column K and L, respectively).
b) If you have finished transcribing a file alert a full-time staff member, update Column J (actual trans. hrs) with the number of hours it took you to complete the transcription, and write the dates of completion of each listen in Column K and L.
For more information about each column in the Transcription Log, please refer to this page in the wiki.
Back to table of contents
Transcribing Video Call Storytime Phase 3 Recordings
The Video Call Storytime (VCST) activity in the Talk Together Study is a recording of an interaction between a parent and child over a video call (Zoom). The Phase/Timepoint 3 VCST recordings includes:
- The parent reading the picture cards/vowel triangle cards to their child in English and their preferred language (Mandarin, Malay, or Tamil). As per protocol change on 15th November 2021, the Picture Cards activity will now be fully transcribed. See point 7(a) below for more details.
- The parent reading “The Little Orangutan: What a Scary Storm” book to their child
The VCST will usually include one Parent (Father or Mother), one Baby, and one Researcher. There may be instances where another person’s voice may appear in the recording (e.g., a sibling of the baby, another family member, etc.)
- Watch the VIDEO recording file in full before you begin transcribing.
- Familiarize yourself with the participants’ voices and any contextual information.
- Note how many participants there are. Identify the participant by their relationship to the baby.
- Note what languages are being spoken.
- Note down the timepoints when the Picture Cards (PC) segment starts and ends for ActivityMarker purposes
- The start of the PC segment is the very start of the recording, including researcher instruction/speech
- The end of the PC segment is usually when the researcher says something along the lines of “That was great! Thank you so much” (indicating that the parents has read through all the necessary cards), or if the parent says something along the lines of “Next. I’m ready to move on to the next activity”.
- Note down the timepoints when the story reading segment starts and ends for ActivityMarker purposes
- The start of the story segment is when the researcher says something along the lines of “I will now switch off my camera. Just remember, once you are ready to go to the next page, you can tell me ‘Next!’ Are you ready? Okay let’s begin”. Ensure you include this researcher instruction/speech within the starting marker.
- The end of the story segment is usually when the parent/child says ‘the end’ or finish recapping the story or finish talking about the orangutan holding pencils on the last page of the book. The ending marker should be placed right before the researcher comes back into the recording and says something along the lines of “Thank you! You and your child looked like you were having so much fun….” If you’re unsure, ask a full-time staff member.
- Note any muffled parts or parts where all speech become indecipherable. Information on how to deal with these parts can be found under Frequently Asked Questions (FAQ).
-
Import the associated AUDIO (.wav) file and the template file (.etf) into ELAN. Refer to the “Transcription Template” section of the wiki on instructions on how to handle the template subsequent to importing it.
-
a) Go to “File” and click “Save” or “Save As” like a normal document. The file should be named according to the file naming conventions outlined on the wiki. You can also set an automatic backup of the file by going to “File” > “Automatic Backup”. Choose a time interval between 1 to 30 minutes that suits your preference. Note: the backup file will be saved with the extension
*.eaf.001.b) Update the transcription log - namely AudioFileName (Column B), TranscribedFileName (Column C), Project (Column D, in this case would be TTS), Audio Length (Column E), Language(s) spoken in the recording (Column G), Transcriber 1 (Column H, which would be your name), Date issued (Column I). It will also help to write down anything of note (e.g., audio dropping at any point, the length of an activity) into the Comments by Transcriber (Column M).
-
In order to see the hierarchical relationship between the dependent tiers, right click on the tier sidebar > Sort Tiers > Sort by Hierarchy.
-
Edit the tier attributes to replace placeholder participant codes with accurate participant ID codes for all the participants present in the recording. This should be done on all the present participant’s primary and secondary tiers.(e.g. the participant ID is
P1234TTand the mother, baby, and researcher (R099) are present in this recording. The Mother codeMPXXXXTTshould be edited toMP1234TTon all the Mother primary and secondary tiers. The Baby codePXXXXTTshould be edited toP1234TTon all the Baby primary and secondary tiers. The Researcher codeR00XPxxxxTTshould be edited toR099P1234TTon all the Researcher primary and secondary tiers). DO NOT DELETE UNUSED TIERS. Right click on the tier panel and hide them if they are getting in your way -
Adjust the vertical zoom (right click on the waveform > Vertical Zoom > adjust the %) and horizontal zoom (adjust the slider at the bottom right of the ELAN screen) to help you see the waveform clearly.
-
Put on your headphones and begin transcribing the PC segment (a) and story reading segment (b) of the audio file.
7a. Transcribing the PC segment
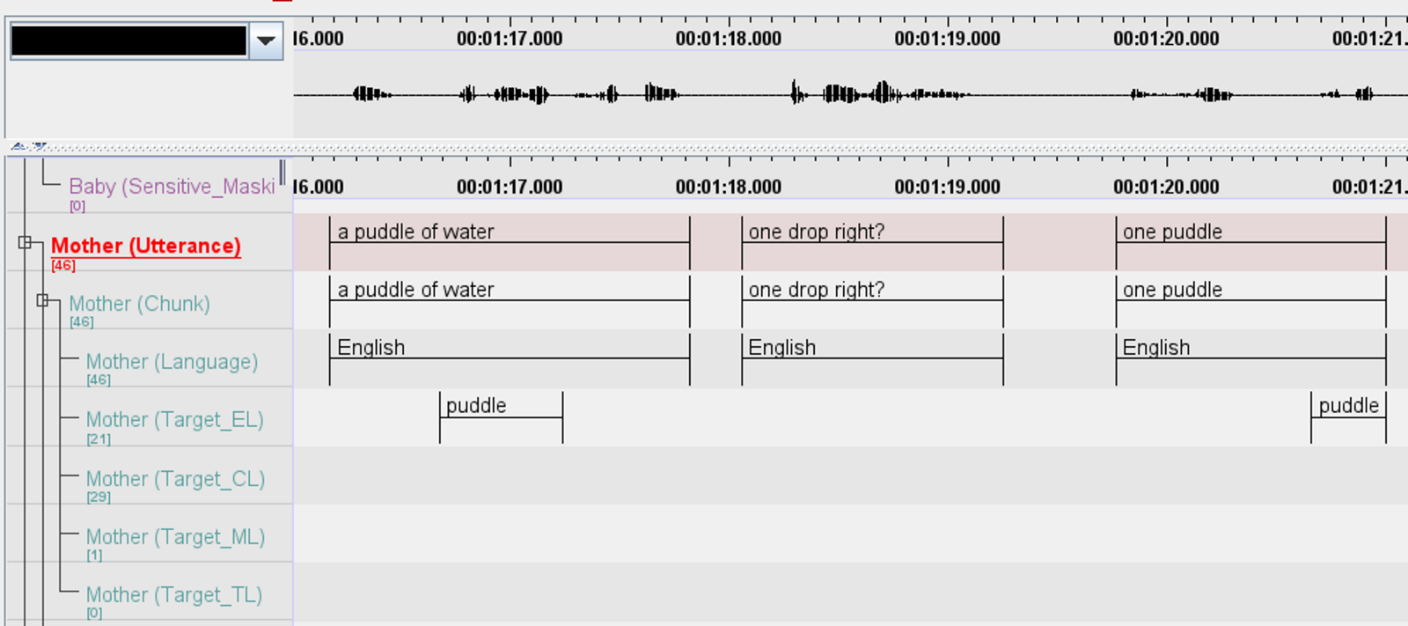
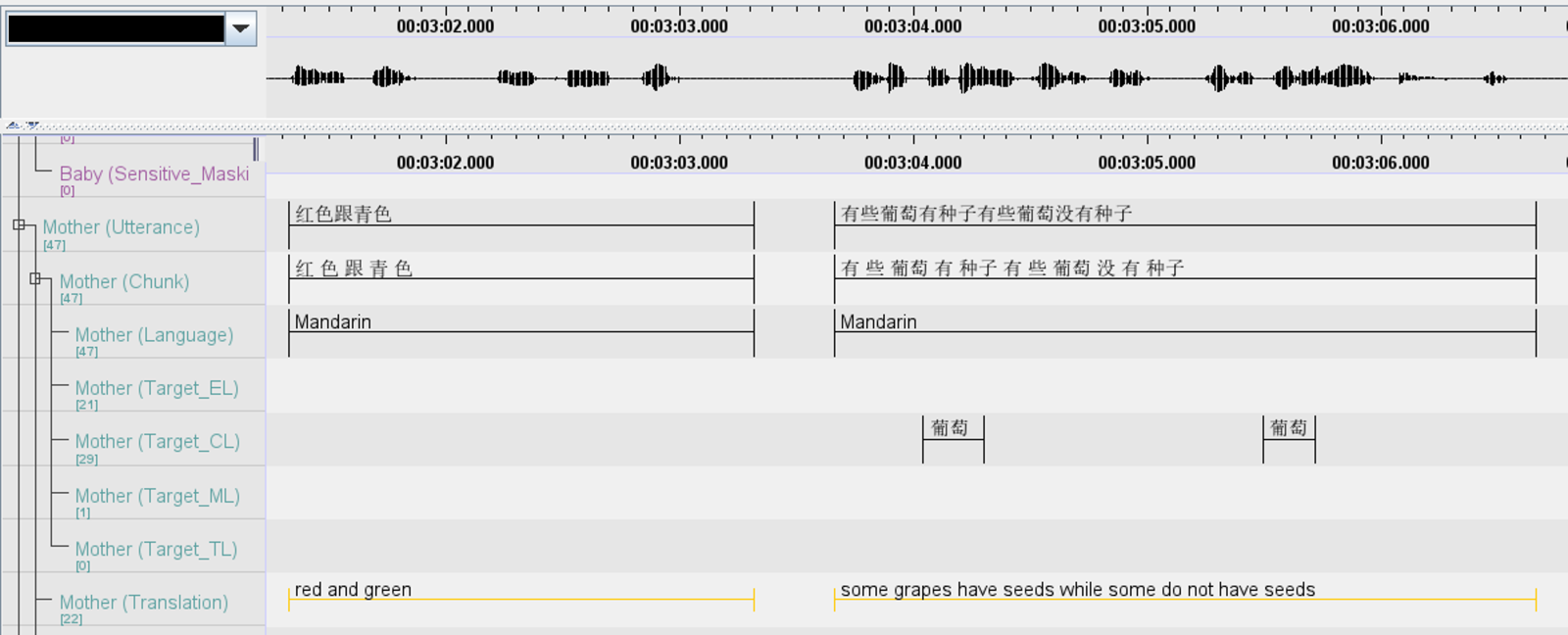
- For the picture cards segment during the timepoint 3 video call story time, transcribers need to also can isolate the target words spoken by the parent or child on the participants’ respective
Targetword tiers (e.g.,Target_ELfor target English words). Please see the two images above as examples. - Target word tiers for the baby do not have a controlled vocabulary assigned to them. Transcribers can freely transcribe any instance of the baby’s attempt at vocalising a target word (e.g., if a baby says ‘pa’ instead of ‘pea’).
- The picture card activity is looking to elicit the following sounds:
- xi (for Mandarin Picture Cards)
- si (for Mandarin Picture Cards)
- pi (for English, Mandarin, Tamil, Malay Picture Cards)
- pa (for English, Mandarin, Tamil, Malay Picture Cards)
- pu (for English, Mandarin, Tamil, Malay Picture Cards)
- For incomplete target words, it is necessary to isolate them in the target word tiers if the target sounds are elicited. See the images below as examples.
Example: in ‘西瓜’ if parent says ‘西’, we should tag it in the Target_CL tier. However, if only ‘瓜’ is said, it is not necessary to label it in the Target_CL tier. This would apply to English, Malay and Tamil as well, whereby in Malay if ‘pa’ was said, it should be indicated in the Target_ML tier but there is no need to do so for ‘dang’.


- At times, parents might say the plural versions of the target words (e.g. peas, partners). In this case, it is still necessary to isolate them in the target word tiers as the target sounds were elicited.


- If target words are spelt out letter by letter i.e. parent says each letter out loud, they do not need to be tagged in the target word tiers. When a word is being said out letter by letter, it should be annotated like this:
p... e... a.... Do refer to the example as shown below.

- Isolate instances (e.g., mention of the baby’s name) that need redacting on the
Sensitive_Maskingtier. Live demo on how to use the Sensitive_Masking tier here. - Use the
Translationtier if you need to translate any non-English utterances into English.
7b. Transcribing the story reading segment
- Transcribe utterances on the
Utterance,Chunk, andLanguagetiers. Use theTranslationtier if you need to translate any non-English utterances into English. - Isolate instances (e.g., mention of the baby’s name) that need redacting on the
Sensitive_Maskingtier. Live demo on how to use the Sensitive_Masking tier here. - What counts as an utterance? Read “A Problem Named Utterance” by Dr. Shamala Sundaray, which can be found here
- Utterances directed to the child and researcher should be separate. For instance, the parent may follow up an utterance to the child with a directive to the researcher, e.g., look at the monkey okay next page what is this. A part of the utterance is instructions directed to the researcher to flip the page during the storybook sharing task. Hence, it should be transcribed as separate utterances: look at the monkey, okay next page, what is this. In general, utterances directed to two different people should be considered as separate utterances. In some cases, prosodic information in the audio file may offer additional information on how to segment the utterance.
- For the picture cards segment during the timepoint 3 video call story time, transcribers need to also can isolate the target words spoken by the parent or child on the participants’ respective
- Decide how to transcribe speech unrelated to storybook reading and unrelated to PC segments.
- There is a difference in transcription protocols and conventions when transcribing utterances related or unrelated to the activities in the audio recording (in this case, storybook reading and PC segments).
- As a general rule of thumb, we wish to transcribe speech that is observed during the story reading and PC segments to understand how parents engage their children in these shared activities. During these activities, there may be speech that is not related to the activities. Examples:
- questions or instructions to researchers (e.g., is the page supposed to turn?, next page),
- requests to pause the task (e.g., sorry can we pause?),
- talks to another person (e.g., Mother turning around to talk to Father that came into the room)
- For the above scenarios, if the parent remains on screen and does not start a completely new task, speech should be transcribed as per normal.
- On the other hand, if the parent leaves the screen or starts a completely new task unrelated to story reading or PC, we will partially transcribe the speech as outlined in Step 9 below.
- In order to decide which conventions should be used, this decision table should be used. If you are still unsure, please check in with any team members for further clarification.
- Partially transcribe speech unrelated to storybook reading or PC segements using the following protocol.
- For the portions before the start and after the end of story reading and PC segments of the audio file, if any speaker is talking, mark the onsets and offsets of each utterance.
- As we only wish to transcribe speech during story reading or PC segments, utterances that occur before the start of story reading (and PC) and utterances that occur after the end of story reading (and PC) should be labelled but do not need to be fully transcribed.
- Utterances that occur during the transition between activity segments (e.g., from Mandarin PC to storybook or from English PC to Mandarin PC) should also be labelled and do not need to be fully transcribed.
- If the utterance only contains speech and vocal sounds, demarcate the onset and offset of the utterance. Type
*untranscribed_speech*(with the asterisks) in the Utterance and Chunk tiers. Then, use the Vocal Sounds tag in the Language tier. There is no need to demarcate the onsets and offsets of different languages or vocal sounds for each utterance. If the Baby makes noises/speaks, follow the same procedure in the Utterance and Chunk tiers, and the Language tag is Vocal Sounds as well. This is the only time Vocal Sounds can be used in the Baby (Language) tier.
- If the utterance only contains non-vocal sounds, it should be labelled with the appropriate tags. Example, if there is clapping,
:s:clappingshould be enclosed in the Utterance and Chunk tiers, while Non Vocal Sounds should be used in the Language tier. Note that the chime sound that plays when the orangutan storybook pages turn should not be transcribed. Mouse clicks should not be transcribed either. Read our section on non-vocal sounds here should you need additional guidance on what non-vocal sounds should be labelled.
- If the utterance contains both non-vocal sounds and speech, the onset and offset of speech and non vocal sounds should be demarcated accordingly. If the chime sound that plays when the orangutan storybook pages turn or mouse clicking sounds happen in between untranscribed speech, there is no need to demarcate them.
- If you hear names or items to be redacted, isolate these instances the in SENSITIVE_MASKING tiers. Refer to this site to see what should be redacted.
- If more than one Sensitive_masking tag appears in an utterance, they should be added by order of which they appear. For example, if the Mother says the sibling’s name followed by some words and then the baby’s name, you should transcribe it as:
*untranscribed_speech* SIBLINGNAME BABYNAMEin the Utterance and Chunk tier. Then isolate the instances of each name in the SENSITIVE_MASKING tier of the Mother.
- If more than one Sensitive_masking tag appears in an utterance, they should be added by order of which they appear. For example, if the Mother says the sibling’s name followed by some words and then the baby’s name, you should transcribe it as:
- IMPORTANT: If you are unsure whether to redact an audio region, please consult the team for a second opinion. It’s important for us to ascertain carefully if an audio region should be redacted or not to protect the privacy of our participants.
NOTE: We recommend future researchers to do Steps 8 and 9 while transcribing the audio file. These steps were done post-hoc when transcribing the Talk Together Study audio files and added into the protocol after. Since July 2023, these steps have been fully integrated into the BLIP lab’s transcription workflow (see Talkathon VCST protocol).
-
Ensure you mark out the start and end of the PC segment and story reading segmentin the recording on the
ActivityMarkerstier. Follow the guidelines in step 1 to get an understanding of where each activity starts and ends. Do consult a full-time staff member should you have any questions.:marker:start:cds_voweltri_Engshould be used to mark the start of the VCST Picture Cards/Vowel Triangles English segment.:marker:end:cds_voweltri_Engshould be used to mark the end of the VCST Picture Cards/Vowel Triangles English segment.:marker:start:cds_voweltri_[language name]should be used to mark the start of the VCST Picture Cards/Vowel Triangles preferred language segment (i.e., Mandarin, Malay, or Tamil).:marker:end:cds_voweltri_[language name]should be used to mark the end of the VCST Picture Cards/Vowel Triangles preferred language segment (i.e., Mandarin, Malay, or Tamil).:marker:start:cds_bookshould be used to mark the start of the Story Reading segment.:marker:end:cds_bookshould be used to mark the end of the Story Reading Segment.- Watch our video here or the read the activity markers section in our tier guide in this wiki should you need more guidance on how the ActivityMarkers tier works.
-
Update the transcription log to note your transcription progress on a given file.
a) If you’re still working on the file, note “ongoing” in Column J (actual trans. hrs) and add the date and amount of audio transcribed in the 1st or 2nd listen column (Column K and L, respectively).
b) If you have finished transcribing a file alert a full-time staff member, update Column J (actual trans. hrs) with the number of hours it took you to complete the transcription, and write the dates of completion of each listen in Column K and L.
For more information about each column in the Transcription Log, please refer to this page in the wiki.
Back to table of contents